

Second work environment
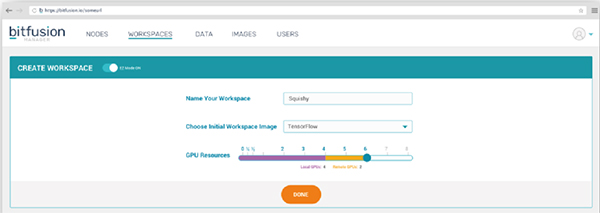
Matrix Fusion pre-installs the mainstream deep learning framework, data science database and GPU driver in the cloud. Users don't need to spend time setting up the development environment. They can complete the development environment setting with a simple mouse click in one minute, and can quickly and flexibly call CPU and GPU resources. .
Intelligent Resource Scheduling
Supporting a wide range of hardware and operating systems, Matrix Fusion provides an end-to-end infrastructure software solution that manages the underlying CPU and GPU computing resources and automates workload provisioning. Deep learning is a typical application that uses both CPU and GPU to handle workloads. Matrix Fusion becomes a CPU+GPU resource pool by integrating all the user's hardware resources (cluster or stand-alone), and then reallocating the CPU and GPU according to the developer's needs. In a developer's virtual environment, administrators can also flexibly allocate redundant computing resources to other users or to more demanding workloads.
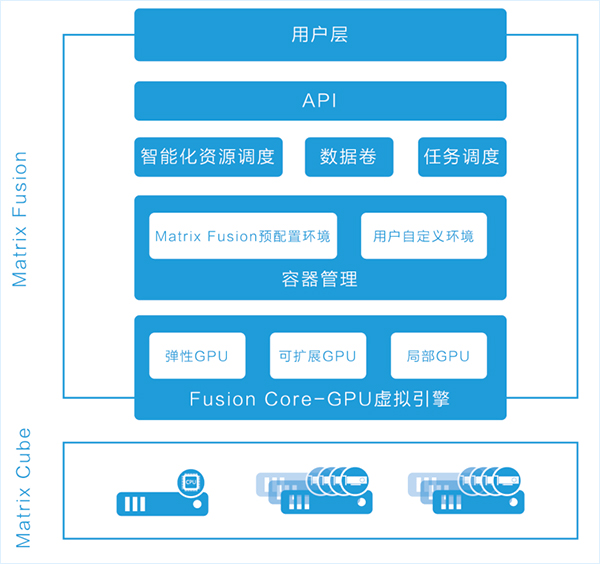
Users can choose to develop on CPU resources in different virtual environments, and then test in GPU resources. When they need to extend training to more GPUs, they can immediately call any number of GPU resources in the virtual environment.
Container Management
Based on powerful computing hardware and GPU virtualization, Matrix Fusion is equipped with a comprehensive container management solution. The core load engine is containerized as the latest technology that greatly simplifies deep learning and AI workflows, investing heavily in money, manpower, and time. Matrix Fusion doesn't need to be personalized, users can log in to the interface and they can directly call the specialized container solution. The Matrix Fusion container management layer includes a built-in repository for managing pre-configured containers (including each deployment scenario or personalization build container): Pre-configured environment: Matrix Fusion pre-configures the latest deep learning framework and data science database. Users can directly use the latest technology versions of TensorFlow, Caffe, Torch and other communities. DIY development environment: Users can use the "workspace snapshot" or "tune into the container" to modify and save the container environment, DIY a development environment that is more suitable for their own usage habits. Matrix Fusion "Load Container" provides users with a simple container (only operating system, minimum configuration database and driver requirements), users modify the environment, and then upload as a standard environment for subsequent development. Users can use the "Docker Save" workflow to copy the environment through the "Workspace Snapshot", modify it and save it to the repository for the next development work. Container Export: Containers can be exported for reasoning or other production deployment requirements.
Fusion Core
The powerful flexibility of Matrix Fusion comes from the Fusion Core computing virtualization engine. The API call indication between the Fusion Core control application and the underlying GPU computing allows the GPU load to be flexibly distributed across local GPU memory, network attached GPUs, and up to 64 GPUs to provide powerful overall performance.
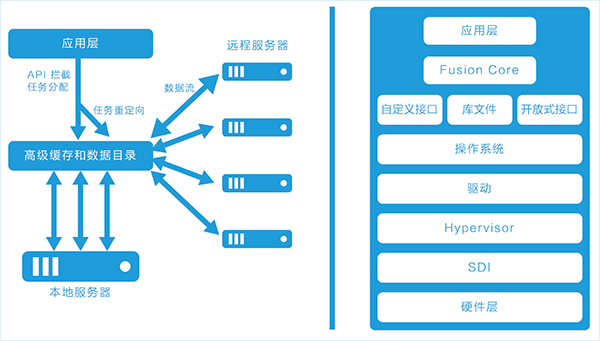
Because Fusion Core uses a "transparent" mode rather than a virtual layer or other virtualization approach, there is no need to make any changes to the underlying hardware or virtual machine environment, nor the application programming itself. This means that AI developers and data scientists can take advantage of GPU virtualization seamlessly and minimize cost and integration requirements.
Data Volume
The data required for deep learning and AI workloads is usually from a wide range of sources, both wired and offline, both external and internal, both bulk and file systems. Matrix Fusion simplifies processing of work data, allowing administrators to identify network attached storage locations and map them to containers. As long as the host has access to the data address, the container can access the data, which greatly simplifies the work of AI developers and data scientists. In addition, the system also supports flexible, unlimited data mapping, Matrix Fusion supports local NFS file system for each node . This default option provides a standard address for the workload, allowing you to quickly get the data you need to run the task, no matter how deep the deep learning workload is running, including running between multiple servers.
